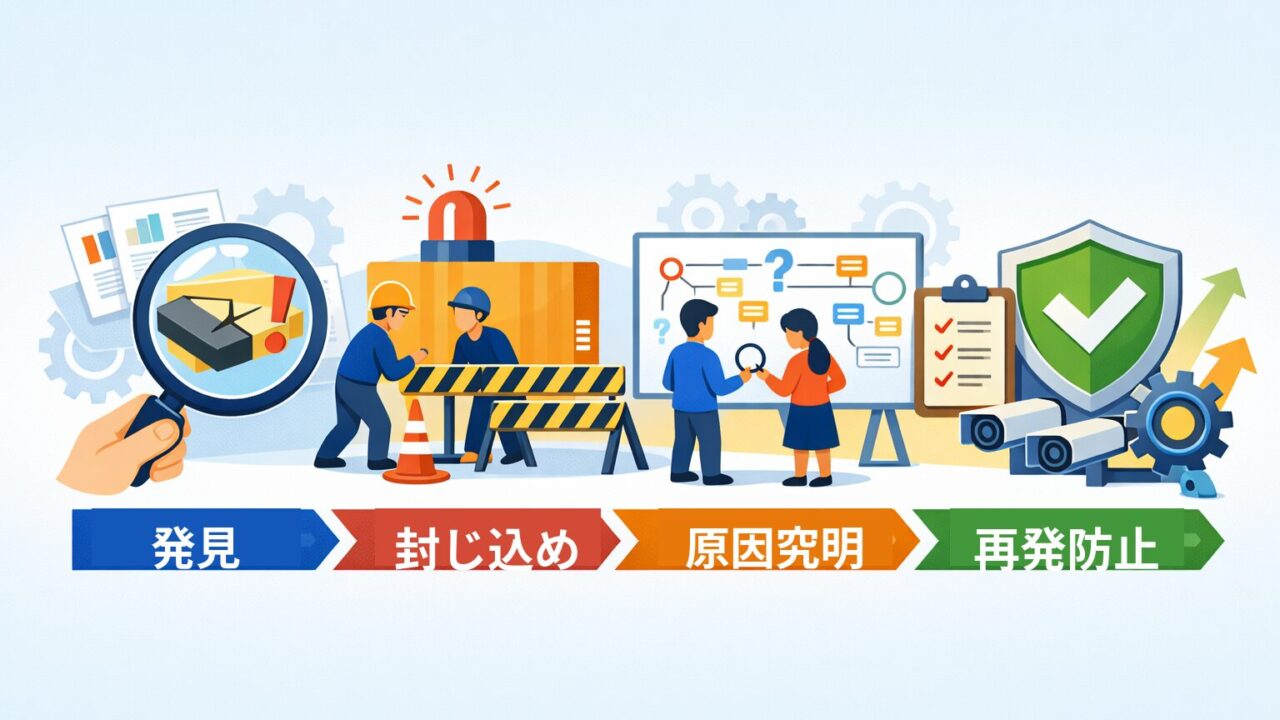
品質トラブル対応の基本4ステップ:発見・封じ込め・原因究明・再発防止
品質トラブル対応は「速さ」と「再発防止」の両立
品質トラブルが起きたとき、現場は一気に混乱します。お客様への影響、納期の遅れ、関係部署への波及、社内外への説明など、判断が必要なことが一度に押し寄せます。
ここで重要なのは、「とにかく直す」だけで終わらせないことです。応急処置だけで収束させると、同じ問題が形を変えて再発し、信頼をじわじわ削ります。
そこで本記事では、初学者でも実務で使える形で、品質トラブル対応を次の4ステップに整理します。
- 発見:状況を把握し、事実を確定する
- 封じ込め:被害拡大を止める(暫定対策)
- 原因究明:真因を特定し、検証する
- 再発防止:仕組みとして定着させる(恒久対策)
ポイントは、この4ステップを順番に“きれいに”進めるのではなく、優先順位を付けて同時並行で回すことです。
4ステップを“同時並行”で回す考え方
トラブル対応でよくある失敗は、いきなり原因究明に飛びつくことです。原因は確かに大事ですが、まずは被害を止めないと状況が悪化してしまいます。
現場での基本はこうです。
- まず封じ込めを最優先(影響を止める)
- その裏で、発見=情報収集と事実確定を進める
- 状況が落ち着いたら、原因究明→再発防止へ重心を移す
イメージとしては、最初の数時間〜1日程度は「封じ込め」が主役、その後に「原因究明」と「再発防止」が主役になっていきます。
PM(またはリーダー)の役割は、チームがパニックにならないように、“今はどのステップを優先しているのか”を明確にし、タスクと責任者を割り当てることです。
ステップ1 発見:情報を集めて事実を固める
発見とは「バグを見つける」だけではありません。トラブル対応でいう発見は、判断できるだけの事実を揃えることです。
発見で最初に確認すること(最低限)
- 何が起きているか(現象)
- どこで起きているか(環境、機能、範囲)
- いつからか(発生タイミング、増加傾向)
- どれくらい影響があるか(ユーザー数、売上影響、業務停止)
- いまも継続中か(再現性、断続的か)
ここでは、推測や犯人探しは不要です。必要なのは「誰が見ても同じ結論になる情報」です。
情報が混乱しているときのコツ
- 口頭情報は必ずメモし、時刻と発言者を残す
- 画面キャプチャ・ログ・設定値・入力データなど、証拠を先に確保する
- 「再現手順」を最短で作る(100%でなくてもよい)
特にログやデータは、復旧対応や再起動で消えることがあります。封じ込めより先に“証拠確保”が必要な場合がある点は覚えておくと強いです。
ステップ2 封じ込め:被害拡大を止める(暫定対策)
封じ込めは、いわば“止血”です。ここでの目的は1つだけ。
お客様・業務への影響をこれ以上増やさない
原因が分からなくても構いません。効果がある暫定手段を打ちます。
封じ込めの代表パターン
- 機能の停止(該当機能だけオフ、フラグで無効化)
- ロールバック(直前の安定版へ戻す)
- トラフィック制御(特定条件のリクエスト遮断、流量制限)
- 手動運用への切り替え(代替手段を用意)
- 影響範囲の隔離(環境切り分け、アカウント制限)
封じ込めは「理想的」より「確実」を優先します。
ただし、暫定対策には副作用もあります。たとえばロールバックで別の既知バグが戻る、機能停止で業務が滞る、などです。
暫定対策の意思決定で押さえる3点
- 効果:どの影響を止められるか
- リスク:副作用・巻き戻しの難しさ
- スピード:何分で実行できるか
PMは、これを短い言葉でまとめて関係者に共有します。
例:「影響拡大を止めるため、該当機能を一時停止。復旧は手動運用で代替。副作用として処理遅延が起きる可能性あり。」
お客様・社内への連絡(初動で大事)
封じ込め中は、説明も同時に必要になります。初動の連絡で大切なのは、確定した事実だけを伝えることです。
- いま分かっている現象
- 影響範囲(暫定でも良いが根拠を示す)
- いま実施中の対応(封じ込め)
- 次回更新の予定(いつ何を報告するか)
「原因は調査中」と言うのはOKですが、推測で断言しないことが信頼につながります。
ステップ3 原因究明:真因にたどり着く(分析と検証)
封じ込めで状況が落ち着いたら、原因究明に移ります。ここでのゴールは次の通りです。
再発防止につながる“真因”を特定する
「なぜ起きたか」だけでなく、「なぜ防げなかったか」まで掘るのがポイントです。
原因究明の進め方(おすすめ手順)
- 事実の時系列を作る(いつ、何が変わったか)
- 切り分け(環境・条件・データ・手順)
- 仮説を立てる(原因候補を複数)
- 検証する(再現、ログ確認、設定差分)
- 真因を確定(再現できる/根拠が揃う)
ここで重要なのは、「それっぽい原因」を見つけて終わらないこと。
再現性や根拠が弱いと、対策も弱くなり、結局再発します。
“なぜなぜ分析”の使いどころ
なぜなぜ分析は便利ですが、使い方を間違えると「精神論」や「犯人探し」になりがちです。実務でのコツは次です。
- “なぜ”は事実に対して問う(推測に問わない)
- 途中で出た答えは、証拠(ログ、仕様、再現)で裏付けする
- 人のせいに見える答え(例:確認不足)が出たら、
「なぜ確認できなかった仕組みなのか」に置き換える
例:
現象「本番で特定条件の注文が失敗した」
- なぜ? → 該当APIが500を返した
- なぜ? → DBの特定カラムがNULLで処理が落ちた
- なぜ? → マイグレーションでデータ変換が漏れた
- なぜ? → 変換対象条件が設計書に明記されていなかった
- なぜ? → 仕様変更が口頭で伝わり、文書とレビューに反映されなかった
→ 真因は「仕様変更の伝達〜レビューのプロセス不備」に寄る、と判断できる
こうすると、再発防止が「注意する」ではなく「プロセス改善」に着地します。
ステップ4 再発防止:仕組みで同じ失敗をなくす(恒久対策)
再発防止の目的は、次の一文に尽きます。
人の頑張りではなく、仕組みで防ぐ
恒久対策は「原因を潰す対策」だけでなく、「検知を早める対策」もセットにします。
恒久対策の典型(技術+プロセス)
- 入力チェック・バリデーション強化
- 例外処理・フォールバック実装
- 自動テスト追加(再現ケースをテスト化)
- 監視・アラート強化(早期検知)
- レビュー観点・チェックリストの更新
- リリース手順の改善(段階リリース、Feature Flag)
- 仕様変更管理の改善(変更票、合意、履歴)
対策の品質を上げる「3つの条件」
- 有効性:同じ条件で再発しない(テストで保証)
- 持続性:運用で回り続ける(手間が増えすぎない)
- 可視性:守られているか監視できる(メトリクス、ログ)
ここまで整って、初めて「再発防止できた」と言えます。
よくある失敗パターンと回避策
失敗1:原因究明が長引き、封じ込めが弱い
→ まず止血。暫定対策を決めて、被害拡大を止める。
失敗2:推測で原因を断定する
→ 根拠(ログ・再現・差分)を揃える。仮説は複数持つ。
失敗3:再発防止が「注意する」「気をつける」になる
→ プロセス・設計・テスト・監視など“仕組み”に落とす。
失敗4:対策が増えすぎて現場が回らない
→ 影響と頻度で優先順位を付け、まず上位3つに絞って確実にやる。
現場で使えるチェックリスト
発見チェック
- 現象を一文で言える
- 影響範囲(ユーザー/機能/環境)を言える
- 発生時刻と直前変更点が分かる
- ログ・データ・証跡を確保した
- 再現手順(暫定でも)を作った
封じ込めチェック
- 影響拡大を止める手段を3案出した
- 効果・副作用・所要時間を比較した
- 暫定対策の実行者と手順が決まった
- 関係者への一次連絡(事実+対応+次回報告)ができた
原因究明チェック
- 時系列が整理できた
- 仮説を複数用意した
- 検証方法(再現/ログ/差分)を決めた
- 真因を裏付ける証拠が揃った
- 「なぜ防げなかったか」も説明できる
再発防止チェック
- 恒久対策が“仕組み”になっている
- 再現ケースがテスト化されている
- 監視・アラートで早期検知できる
- 運用やレビューの観点が更新された
- 対策の優先順位と期限・担当が決まった
まとめ
品質トラブル対応は、発見・封じ込め・原因究明・再発防止の4ステップで整理すると、混乱の中でも判断しやすくなります。最初は「封じ込め」で被害拡大を止め、同時に「発見」で事実を固め、落ち着いたら「原因究明」で真因を特定し、「再発防止」で仕組みに落とす。
この流れをテンプレ化しておくと、トラブル時でもチームが迷いにくくなり、結果としてお客様への影響も、現場の消耗も減らせます。